 Dansday
Dansday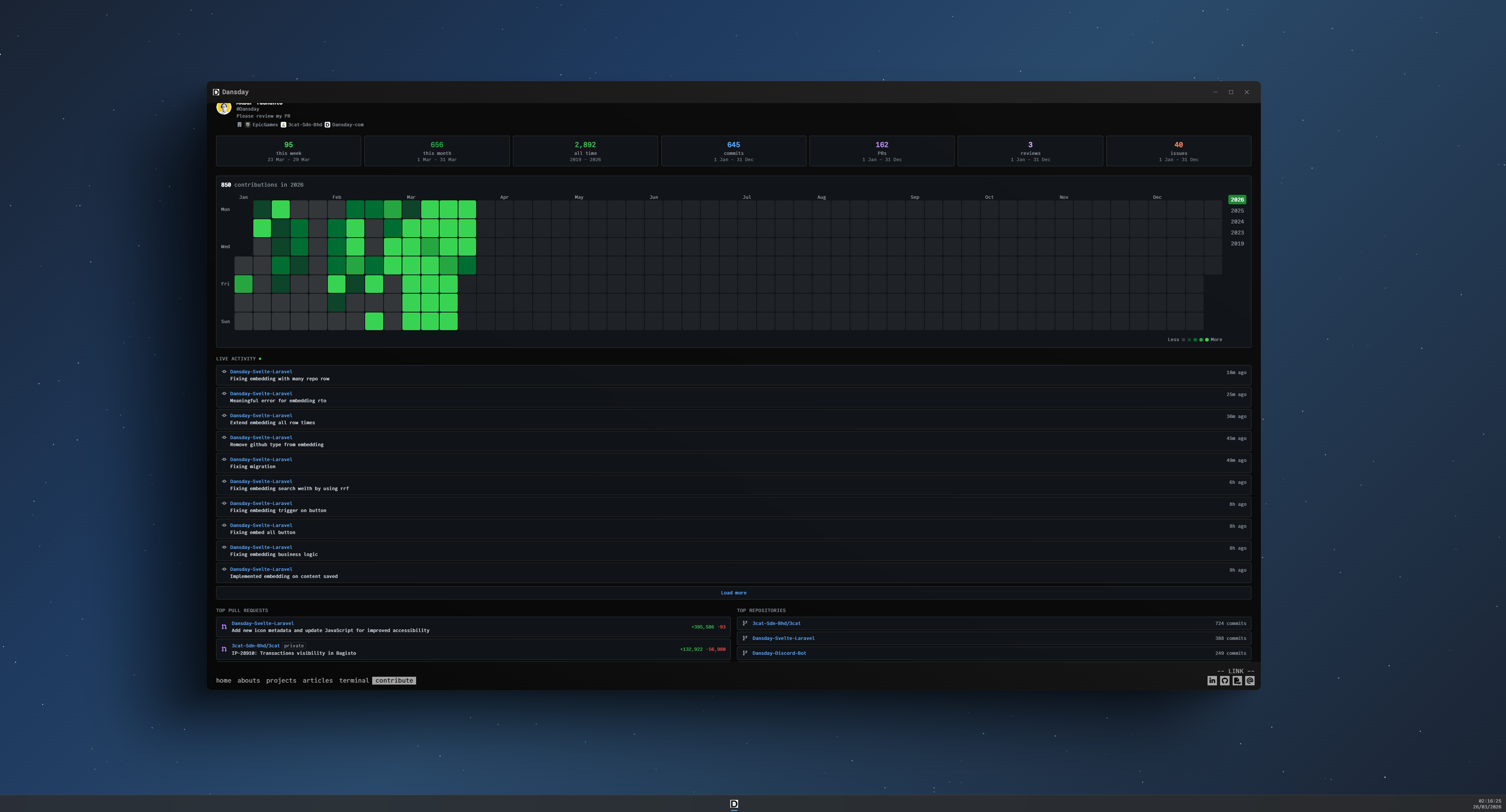
When I first tried to surface my GitHub contributions on the site I hit two clear roadblocks. Hitting the GitHub GraphQL API on every request was painfully slow and ate up my rate limits. At the same time I needed a way to run semantic search over the activity text, which meant I had to generate a vector representation for each item.
My answer was to move all of the heavy lifting into a background sync that runs every six minutes. The job pulls commits, pull requests, reviews and issues from the GitHub GraphQL API, stores every row in a MySQL table and then writes aggregated statistics into Redis. After the data lands in the database I batch any rows that lack a vector, send them to an embedding API, and save the resulting vectors back to the same table. Orphaned vectors are cleaned up in the same pass so the store never drifts.
Because the sync updates a Redis timestamp before it starts, overlapping cycles never happen. I insert rows with INSERT IGNORE using a unique identifier, which silently drops duplicates and keeps the job idempotent. Stats are serialized as JSON under a single Redis key, while per‑year calendar data gets its own key for instant lookup.
The frontend reads exclusively from Redis and MySQL. A single /api/github endpoint serves the first page with cached stats and the most recent activity. As the visitor scrolls, additional pages are fetched directly from the database, giving me infinite scroll without ever touching GitHub again. All of the visible elements a contribution calendar you can browse by year, stat cards broken down by week month year and all time, a live activity feed, top pull requests ranked by lines changed and top repositories ranked by commit count – are rendered from this cache. Private repositories are masked but still appear in the feed.
- Why I built it this way I needed fast page loads and a way to stay within GitHub rate limits. Caching everything locally lets me respond instantly and eliminates external calls during a visitor request.
- The problem it solves Latency and rate limits on the GitHub API disappear, and I gain the ability to paginate, filter and aggregate data without additional network hops.
- Tradeoffs I considered The only downside is a possible six minute window of staleness. In practice users never notice the delay and the performance gain outweighs it.
- How I use it daily I monitor the Redis timestamp to make sure the sync runs on schedule, and I occasionally query the vector store to verify that semantic search returns relevant contributions even when the keyword match is weak.
All of the visitor experience – from the instant calendar switch to the smooth slide in of new activity – comes from data that lives in my own stack. No request ever reaches the GitHub API directly, which means the page loads fast and I never have to worry about hitting rate limits again.